Scale Cluster with CA
Visualizing Cluster Autoscaler Logs and Actions
During this section we recommend arranging your window so that you can see Cloud9 Console and Kube-ops-view and starting a new terminal in Cloud9 to tail Cluster Autoscaler logs. This will help you visualize the effect of your scaling commands.
Execute the following command on Cloud9 terminal
kubectl get svc kube-ops-view | tail -n 1 | awk '{ print "Kube-ops-view URL = http://"$4 }'
Execute the following command on Cloud9 terminal
kubectl logs -f deployment/cluster-autoscaler-aws-cluster-autoscaler -n kube-system --tail=10
Scaling down to 0
Before we scale up our cluster let’s explore what would happen when set up 0 replicas. Execute the following command:
kubectl scale deployment/monte-carlo-pi-service --replicas=0
Question: Can you predict what would be the result of scaling down to 0 replicas?
The configuration that we applied to procure our node groups states that the minimum number of instances in the auto scaling group is 0 for both node groups. Starting from 1.14 version Cluster Autoscaler supports scaling down to 0.
By setting the number of replicas to 0, Cluster Autoscaler will detect that the current instances are idle and can be removed to the min_size of the Auto Scaling Group. This may take up to 3 minutes. Cluster autoscaler will log lines such as the one below flagging that the instance is unneeded.
I1120 00:22:37.204988 1 static_autoscaler.go:382] ip-192-168-54-241.eu-west-1.compute.internal is unneeded since 2021-03-20 00:21:16.651612719 +0000 UTC m=+4789.747568996 duration 1m20.552551794s
After some time, you should be able to confirm that running kubectl get nodes return only our 2 initial On-Demand nodes:
$ kubectl get nodes --label-columns=eks.amazonaws.com/capacityType
NAME STATUS ROLES AGE VERSION CAPACITYTYPE
ip-192-168-165-163.ap-southeast-1.compute.internal Ready <none> 4h1m v1.21.4-eks-033ce7e ON_DEMAND
ip-192-168-99-237.ap-southeast-1.compute.internal Ready <none> 4h1m v1.21.4-eks-033ce7e ON_DEMAND
NOTE: Check in the AWS console that Spot auto-scaling groups have now the Desired capacity set to 0. You can follow this link to get into the Auto Scaling Group AWS console. If there’s a node group that haven’t scale down yet, and you want to confirm this behavior, you might need to wait around 10 more minutes.
Scale our ReplicaSet
OK, let’s now scale out the replicaset to 3
kubectl scale deployment/monte-carlo-pi-service --replicas=3
You can confirm the state of the pods using
kubectl get pods --watch
NAME READY STATUS RESTARTS AGE
monte-carlo-pi-service-584f6ddff-fk2nj 1/1 Running 0 103s
monte-carlo-pi-service-584f6ddff-fs9x6 1/1 Running 0 103s
monte-carlo-pi-service-584f6ddff-jst55 1/1 Running 0 103s
You should also be able to visualize the scaling action using kube-ops-view. Kube-ops-view provides an option to highlight pods meeting a regular expression. All pods in green are monte-carlo-pi-service pods.
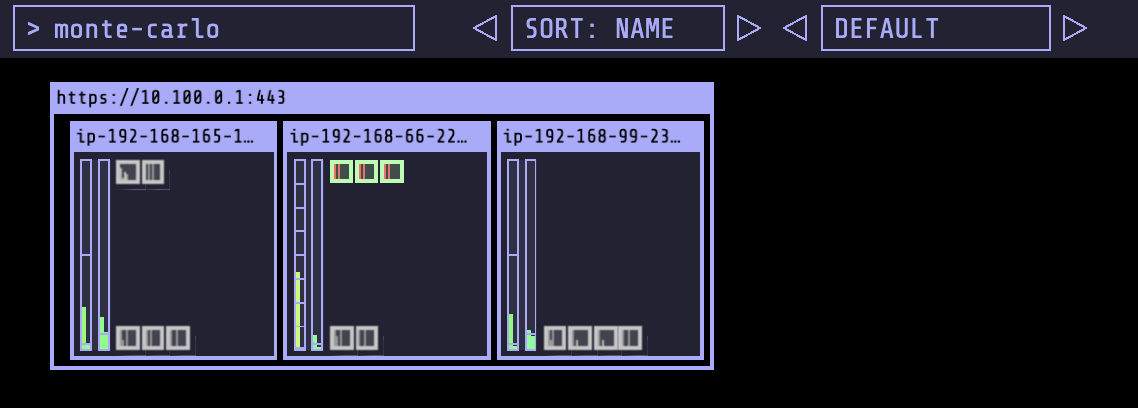
Given we started from 0 nodes in both Spot node groups, this should trigger a scaling event for Cluster Autoscaler. Can you predict which size (and type!) of node will be provided?
Challenge
Try to answer the following questions:
- Could you predict what should happen if we increase the number of replicas to 20?
- How would you scale up the replicas to 20?
- If you are expecting a new node, which size will it be: (a) 4vCPU’s 16GB RAM or (b) 8vCPU’s 32GB RAM?
- Which EC2 Instance type you would expect to be selected?
- How would you confirm your predictions?
- Would you consider the selection of nodes by Cluster Autoscaler as optimal?
To scale up the number of replicas run:
kubectl scale deployment/monte-carlo-pi-service --replicas=20
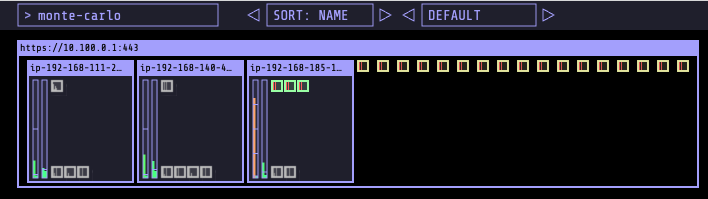
When the number of replicas scales up, there will be pods pending. You can confirm which pods are pending by running the command below.
kubectl get pods --watch
Kube-ops-view, will show pending yellow pods outside the node.
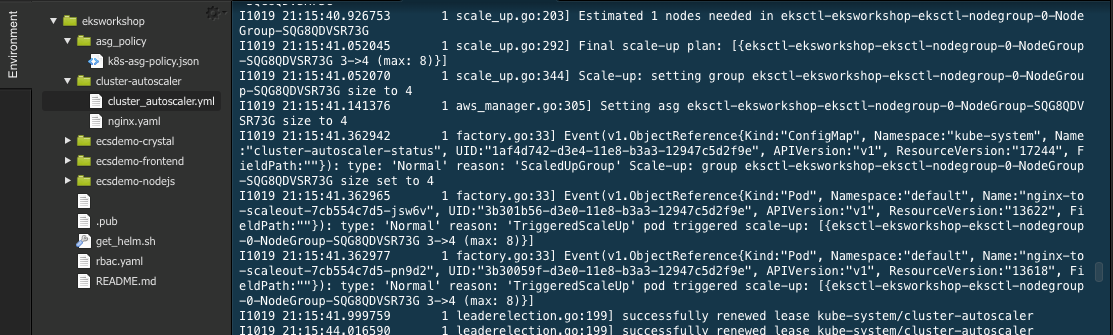
When inspecting cluster-autoscaler logs with the command line below.
kubectl logs -f deployment/cluster-autoscaler-aws-cluster-autoscaler -n kube-system
you will notice Cluster Autoscaler events similar to:
To confirm which type of node has been added you can either use kube-ops-view or execute:
kubectl get node --selector=intent=apps --show-labels
You can verify in AWS Management Console to confirm that the Auto Scaling groups are scaling up to meet demand. This may take a few minutes. You can also follow along with the pod deployment from the command line. You should see the pods transition from pending to running as nodes are scaled up.
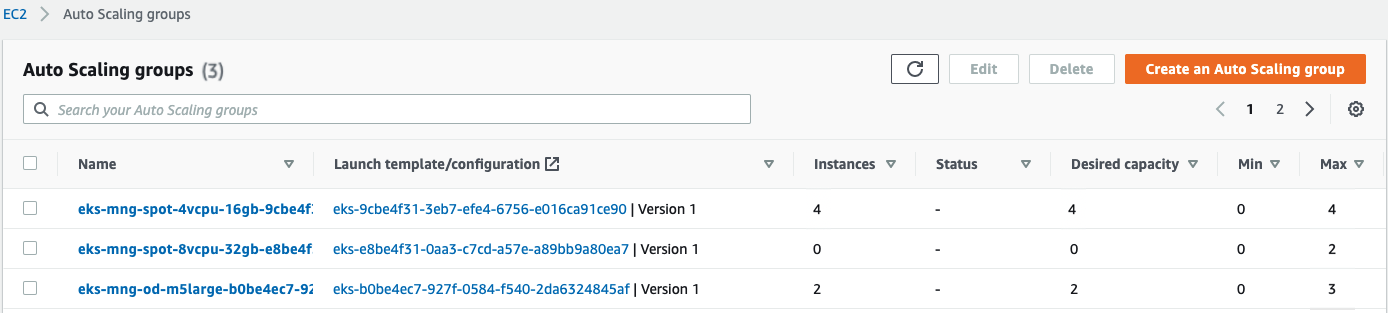
NOTE: Cluster Autoscaler expands capacity according to the Expander configuration. By default, Cluster Autoscaler uses the random expander. This means that there is equal probability of cluster autoscaler selecting the 4vCPUs 16GB RAM group or the 8vCPUs 32GB RAM group. You may consider also using other expanders like least-waste, or the priority expander.
As for the EC2 Instance type that was selected, by default the Auto Scaling groups that we created use the capacity-optimized allocation strategy, this makes the Auto Scaling group procure capacity from the pools that has less chances of interruptions.
After you’ve completed the exercise, scale down your replicas back down in preparation for the configuration of Horizontal Pod Autoscaler.
kubectl scale deployment/monte-carlo-pi-service --replicas=3
Optional Exercises
Some of this exercises will take time for Cluster Autoscaler to scale up and down. If you are running this workshop at a AWS event or with limited time, we recommend to come back to this section once you have completed the workshop, and before getting into the cleanup section.
-
What will happen when modifying Cluster Autoscaler expander configuration from random to least-waste. What happens if we increase the number of replicas to 40? Can you predict which node group will be expanded in each case: (a) 4vCPUs 16GB RAM (b) 8vCPUs 32GB RAM? What’s Cluster Autoscaler log looking like in this case?
-
How would you expect Cluster Autoscaler to Scale in the cluster? How about scaling out? How much time you’ll expect for it to take?
-
How will pods be removed when scaling down? From which nodes they will be removed? What is the effect of adding Pod Disruption Budget to this mix?
-
Scheduling in Kubernetes is the process of binding pending pods to nodes, and is performed by a component of Kubernetes called kube-scheduler. When running on Spot the cluster is expected to be dynamic; the state is expected to change over time; The original scheduling decision may not be adequate after the state changes. Could you think or research for a project that could help address this? (hint_1) hint_2. If so apply the solution and see what is the impact on scale-in operations.
-
During the workshop, we used node groups that expand across multiple AZ’s; There are scenarios where might create issues. Could you think which scenarios? (hint). Could you think of ways of mitigating the risk in those scenarios? (hint 1, hint 2)