EC2 Spot deployments
 Please note: this EKS and Karpenter workshop version is now deprecated since the launch of Karpenter v1beta, and has been updated to a new home on AWS Workshop Studio here: Karpenter: Amazon EKS Best Practice and Cloud Cost Optimization.
Please note: this EKS and Karpenter workshop version is now deprecated since the launch of Karpenter v1beta, and has been updated to a new home on AWS Workshop Studio here: Karpenter: Amazon EKS Best Practice and Cloud Cost Optimization.
This workshop remains here for reference to those who have used this workshop before, or those who want to reference this workshop for running Karpenter on version v1alpha5.
In the previous sections we’ve already used EC2 Spot instances. We have learned so far that when using EC2 Spot Karpenter selects a diversified list of instances and uses the allocation strategy price-capacity-optimized to select the EC2 Spot pools that are optimal to reduce the frequency of Spot terminations while still being ideal for reducing the waste of the pending pods to place.
In this section we will look at how Karpenter handles Spot interruptions and set up the node termination handler to gracefully handle rebalancing recommendation signals since Karpenter does not currently support rebalance recommedations. To support this configuration we will use the default Provisioner.
Before moving to the exercises. Let’s apply Spot Best practices and make sure we handle Spot instances properly from now on.
How do Spot Interruptions Work?
When users requests On-Demand Instances from a pool to the point that the pool is depleted, the system will select a set of Spot Instances from the pool to be terminated. A Spot Instance pool is a set of unused EC2 instances with the same instance type (for example, m5.large), operating system, Availability Zone, and network platform. The Spot Instance is sent an interruption notice two minutes ahead to gracefully wrap up things.
Amazon EC2 terminates, your Spot Instance when Amazon EC2 needs the capacity back (or the Spot price exceeds the maximum price for your request). More recently Spot instances also support instance rebalance recommendations. Amazon EC2 emits an instance rebalance recommendation signal to notify you that a Spot Instance is at an elevated risk of interruption. This signal gives you the opportunity to proactively rebalance your workloads across existing or new Spot Instances without having to wait for the two-minute Spot Instance interruption notice.
Karpenter and Spot Interruptions
Karpenter natively handles Spot Interruption Notifications (as of v0.19.0) by consuming events from an SQS queue which is populated with Spot Interruption Notifications via EventBridge. All of the infrastructure is setup by Karpenter’s CloudFormation template that was applied previously. When Karpenter receives a Spot Interruption Notification, it will gracefully drain the interrupted node of any running pods while also provisioning a new node for those pods to quickly schedule onto.
Karepnter does not yet support Rebalance Recommendation signals, so to capture these signals and handle graceful termination of our nodes, we can deploy a project called AWS Node Termination Handler. Node termination handler operates in two different modes Queue Mode and Instance Metadata Mode. When using Instance Metadata Mode, the aws-node-termination-handler will monitor the Instance Metadata Service with a small pod running as a (DaemonSet) on each host. The DaemonSet will perform monitoring of IMDS paths like /spot and /events and react accordingly to drain and/or cordon the corresponding node.
We will not deploy the Node-Termination-Handler in this workshop since we are using Karpenter’s native Spot Interruption handling. But the Node-Termination-Handler is required if you need to handle Rebalance Recommendation signals and can be run safely with Karpenter’s Spot Interruption Handling.
Create a Spot Deployment
Let’s create a deployment that uses Spot instances.
cat <<EOF > inflate-spot.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate-spot
spec:
replicas: 0
selector:
matchLabels:
app: inflate-spot
template:
metadata:
labels:
app: inflate-spot
spec:
nodeSelector:
intent: apps
karpenter.sh/capacity-type: spot
containers:
- image: public.ecr.aws/eks-distro/kubernetes/pause:3.2
name: inflate-spot
resources:
requests:
cpu: "1"
memory: 256M
EOF
kubectl apply -f inflate-spot.yaml
When dealing with disruptions, it is important your application can shutdown safely by handling the SIGTERM signal. A SIGTERM signal is sent to the main process (PID 1) of each container in the Pods being evicted. After the SIGTERM signal is sent, Kubernetes will give the process some time (grace period) before a SIGKILL signal is sent. This grace period is 30 seconds by default; you can override the default by using grace-period flag in kubectl or declare terminationGracePeriodSeconds in your Pod spec. For more information on dealing with disruptions checkout the reliability section of the Amazon EKS best practices guide.
Challenge
You can use Kube-ops-view or just plain kubectl cli to visualize the changes and answer the questions below. In the answers we will provide the CLI commands that will help you check the resposnes. Remember: to get the url of kube-ops-view you can run the following command kubectl get svc kube-ops-view | tail -n 1 | awk '{ print "Kube-ops-view URL = http://"$4 }'
Answer the following questions. You can expand each question to get a detailed answer and validate your understanding.
1) Scale up the number of Spot replicas to 2.
Let’s start with increasing the number of replicas for the inflate-spot deployment to 2. Run the following command
kubectl scale deployment inflate-spot --replicas 2
Observe a Spot node provisioned in response to scaling the inflate-spot deploy to 2 replicas:
kubectl get node --selector=intent=apps -L kubernetes.io/arch -L node.kubernetes.io/instance-type -L karpenter.sh/provisioner-name -L topology.kubernetes.io/zone -L karpenter.sh/capacity-type
2) (Optional) Is that all for EC2 Spot Best practices?
Hmmmm nope… There are a few things that may worth advancing on what’s to come with Karpenter
- There are plans in Karpenter to handle rebalancing recommendation signals. Rebalancing recommendation signals will allow Karpenter to procure new capacity in advance to a termination event and speed up the provisioning of instances. This functionality is already available in Spot Managed Node groups and Self Managed Node Groups with the help of the AWS Node Termination Handler.
The following diagram depicts how the integration will consider rebalancing recommendations in the future. The diagram shows how when a rebalancing recomendation arrives indicating an instance is at elevated risk of termination, the controller will provision new instances using price-capacity-optimized. This has the effect of rebalancing instances proactively and selecting them from the optimal pools that reduce the frequency of terminations. Once the new node is up and ready, the controller will follow node termination best practices to decommission the node at elevated risk of termination using cordon and drain, so that the pods migrate into the newly created instance.
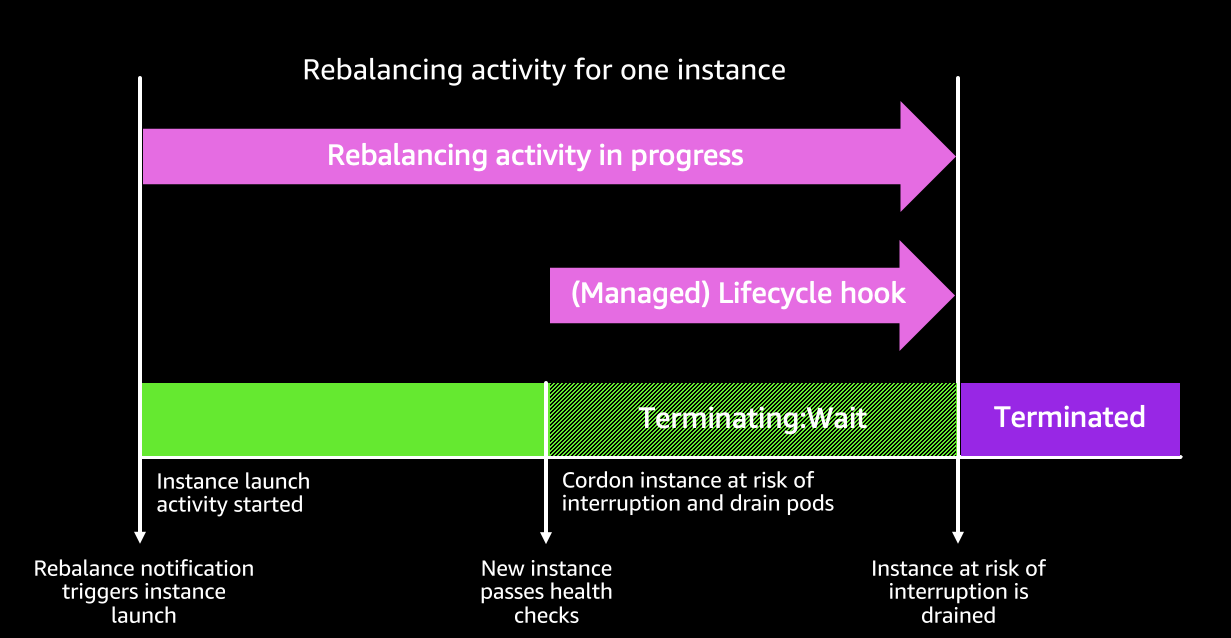
-
One question that comes up often is “what happens if the instances I selected cannot be provisioned?”. Since version v0.6.0 Karpenter prioritizes Spot offerings if the provisioner allows Spot and On-Demand instances. If the provider API (e.g. EC2 Fleet’s API) indicates Spot capacity is unavailable, Karpenter caches that result across all attempts to provision EC2 capacity for that instance type and zone for the next 3 minutes. If there are no other possible offerings available for Spot, Karpenter will attempt to provision on-demand instances, generally within milliseconds.
-
The scenario where Karpenter cannot provision specific selected instances can happen with other configurations. In general since v0.4.0 Karpenter can use soft affinities (
preferredDuringSchedulingIgnoredDuringExecution) so that, if for whatever reason Karpenter cannot satisfy this condition, Karpenter will remove the soft constraint.
3) Scale both deployments to 0 replicas ?
Before moving to the next section let’s set the replicas down to 0
kubectl scale deployment inflate-spot --replicas 0
What Have we learned in this section :
In this section we have learned:
-
How to apply Spot best practices and use Karpenter to handle Spot interruptions.
-
How future versions of Karpenter will enable a better integration of Spot Best practices by proactively managing rebalancing signals.